
Contenido
1. Cláusulas de consulta
Las cláusulas de consulta son herramientas poderosas en SQL que nos permiten filtrar, ordenar y agrupar datos según nuestros criterios específicos. Ya hemos visto la sintaxis básica y algunas consultas muy simples en la unidad anterior, pero ahora veremos como filtrar los datos mediante distintas sentencias para poder gestionar la información que deseamos obtener. A continuación, detallaré las cláusulas más comunes en SQL,
1.1 Filtrar consultas con WHERE
La sentencia WHERE se utiliza para especificar o filtrar consultas mediante parámetros, estos parámetros pueden hacer referencia a una o varias de las columnas dentro de una tabla.
En el siguiente ejemplo se muestra como consultar utilizando las columnas Nombre y DNI de la tabla Empleados y mediante la sentencia WHERE especificamos que nos muestre únicamente aquellos que tienen un salario mayor a 2000 dólares.
Sintaxis:
-- SINTAXIS
SELECT columnas FROM tabla WHERE condicion;
-- EJEMPLO 1
SELECT Nombre, DNI
FROM Empleados
WHERE Salario > 2000;
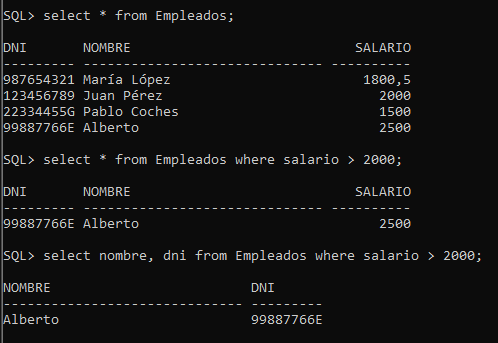
Ejemplo: En este ejemplo con la sentencia SELECT seleccionamos todas las columnas (Con el símbolo * hacemos referencia a todas las columnas), con FROM indicamos la tabla Empleados y finalmente con WHERE filtramos por los departamentos de «Ventas».
SELECT *
FROM Empleados
WHERE Departamento = 'Ventas';
1.1.1 Operadores de Concatenación;
En SQL, puedes utilizar diferentes operadores de concatenación dependiendo del sistema de gestión de bases de datos que estés utilizando. En SQL*Plus por ejemplo, que es una herramienta de línea de comandos para Oracle Database, puedes utilizar el operador || para concatenar valores de columna o cadenas de texto.
Aquí tienes un ejemplo de cómo puedes utilizar el operador de concatenación || en SQL:
SELECT columna1||columna2 FROM nombre_tabla WHERE referencia;
SELECT DNI||NOMBRE FROM Empleados WHERE Salario > 2000;

SELECT DNI||NOMBRE AS "Empledados con un salario mayor a 2000" FROM Empleados WHERE Salario > 2000;

SELECT columna1 || ' ' || columna2 AS alias
FROM tu_tabla;
En esta consulta:
columna1ycolumna2son los nombres de las columnas de tu tabla que deseas concatenar.' 'es una cadena de texto que contiene un espacio en blanco. Puedes utilizar cualquier cadena de texto que desees para separar las columnas concatenadas.ASse utiliza para asignar un alias opcional que puedes utilizar para el resultado concatenado.
Esta consulta concatenará los valores de columna1 y columna2, separados por un espacio en blanco, y mostrará el resultado en una sola columna llamada concatenado.
SELECT 'El nombre es '||nombre||' y su dni '||dni AS "Tabla de DNI y nombres" FROM Empleados;

1.1.2 Operadores de Comparación;
Estos operadores te permiten realizar diversas comparaciones en una sentencia SQL para filtrar los resultados según tus criterios. Dependiendo de la base de datos específica que estés utilizando, puede haber otros operadores disponibles, pero estos son los más comunes y ampliamente compatibles.
Los operadores de comparación que puedes utilizar en la cláusula WHERE en SQL:
Igualdad (
=): Compara si dos valores son iguales.Desigualdad (
<>o!=): Compara si dos valores no son iguales.Mayor que (
>): Compara si un valor es mayor que otro.Menor que (
<): Compara si un valor es menor que otro.Mayor o igual que (
>=): Compara si un valor es mayor o igual que otro.Menor o igual que (
<=): Compara si un valor es menor o igual que otro.Comparación de texto (
LIKE): Compara si un valor coincide con un patrón de texto utilizando caracteres comodín.En un rango (
BETWEEN): Compara si un valor está dentro de un rango específico.No está en un rango (
NOT BETWEEN): Compara si un valor no está dentro de un rango específico.
Igualdad (=)
Compara si dos valores son iguales.
SELECT * FROM tabla WHERE columna = valor;
Desigualdad (<> o !=)
Compara si dos valores no son iguales.
SELECT * FROM tabla WHERE columna <> valor;
SELECT * FROM tabla WHERE columna != valor;
Mayor que (>)
Compara si un valor es mayor que otro.
SELECT * FROM tabla WHERE columna > valor;
Menor que (<)
Compara si un valor es menor que otro.
SELECT * FROM tabla WHERE columna < valor;
Mayor o igual que (>=)
Compara si un valor es mayor o igual que otro.
SELECT * FROM tabla WHERE columna >= valor;
Menor o igual que (<=)
Compara si un valor es menor o igual que otro.
SELECT * FROM tabla WHERE columna <= valor;
Comparación de texto (LIKE)
Compara si un valor coincide con un patrón de texto utilizando caracteres comodín.
SELECT * FROM tabla WHERE columna LIKE 'patron%';
Por ejemplo, en el caso de querer filtrar por todas las columnas que empiezen por la letra «A» asignaríamos la sentencia LIKE ‘A%’:
SELECT * FROM tabla WHERE columna LIKE 'A%';
‘%’ : Indica que contiene contenido. Si por ejemplo filtramos por «%se%» filtrará por los resultados que contengan los valores «se» con contenido delante y detrás como por ejemplo «user».
Es importante recordar que los valores que introduzcamos en la sentencia LIKE diferencia entre mayúsculas y minúsculas, por lo que si filtramos por ‘U%’, únicamente nos mostrará los resultados que empiezan por U mayúscula.
A continuación podemos ver otras opciones de como filtrar datos que también incluirían el resultado «USER».
SELECT * FROM tabla WHERE columna LIKE '%US_%R';
-- Filtra por todos aquellos valores que empiezen por U y terminen por R mayúsculas.
SELECT * FROM tabla WHERE columna LIKE 'U%R';
-- Filtra por mayúsculas y minúsculas.
SELECT * FROM tabla WHERE columna LIKE 'U%R' OR columna LIKE 'u%r';
En un rango (BETWEEN)
Compara si un valor está dentro de un rango específico.
SELECT * FROM tabla WHERE columna BETWEEN valor_minimo AND valor_maximo;
No está en un rango (NOT BETWEEN)
Compara si un valor no está dentro de un rango específico.
1.1.3 Operadores lógicos
Una condición lógica combina el resultado de dos condiciones de componentes para producir un resultado único basado en dichas condiciones. Puede también invertir el resultado de una condición única i se utiliza el NOT.
- AND : Devuelve TRUE si ambas condiciones de componente son TRUE
- OR : Devuelve TRUE si cualquier condición de componente es TRUE
- NOT: Devuelve TRUE si la condición es FALSE.

1.2 Eliminar filas duplicadas con DISTINCT
La visualización por defecto de las consultas incluye todas las filas, y por tato, también incluye las filas duplicadas.
Para eliminar filas duplicadas en el resultado de una consulta podemos utilizar la sentencia DISTINCT tras la sentencia SELECT. Esto solo elimina la repetición de la colsulta, en ningún momento estamos modificando valores de las tablas de la base de datos.
SELECT DISTINCT Nombre FROM Empleados

1.3 Operador ORDER BY
La sentencia ORDER BY en SQL se utiliza para ordenar los resultados de una consulta en función de uno o más campos. Permite especificar el orden en el que se deben devolver las filas de un conjunto de resultados. Aquí tienes una explicación más detallada:
SELECT columnas
FROM tabla
ORDER BY columna [ASC | DESC];
ASC|DESC: Opcionalmente, puedes especificar el orden de clasificación de los resultados.ASCordena los resultados de forma ascendente (predeterminado), mientras queDESClos ordena de forma descendente.
Ejemplos:
Ordenar los resultados en función de una sola columna:
SELECT nombre, edad
FROM personas
ORDER BY edad DESC;
Esto devolverá los nombres y edades de las personas ordenadas de mayor a menor edad.
Ordenar los resultados en función de múltiples columnas:
SELECT nombre, apellido, edad
FROM personas
ORDER BY apellido ASC, edad DESC;
1.4 Funciones de agregación GROUP BY y HAVING
Para aprovechar al máximo SQLPlus y realizar consultas más avanzadas, es fundamental comprender y dominar las sentencias GROUP BY y HAVING. Estas sentencias permiten agrupar y filtrar datos de manera efectiva, brindando un mayor control sobre los resultados de nuestras consultas. En este artículo, exploraremos en detalle cómo utilizar estas sentencias para realizar análisis de datos más sofisticados en SQL*Plus.
En primer lugar debemos de conocer las principales funciones de agregación:
- SUM() : Crea un sumatorio de los resultados seleccionados.
- Count() : Cuenta los valores de los resultados seleccionados.
- AVG() : Calcula el valor promedio.
- MAX() : Devuelve el valor máximo de un conjunto de valores. Ignora los valores nulos.
- MIN() : Devuelve el valor mínimo de un conjunto de valores. Ignora los valores nulos.
- STDDEV(): Calcula la desviación estándar de un conjunto de valores. Ignora los valores nulos.
- VARIANCE(): Función que calcula la varianza de un conjunto de valores. Ignora los valores nulos.
/* Ejemplo: una consulta que muestre el apellido del empelado que sea el primero ordenado alfabéticamente,
y el apellido del último empleado ordenado alfabéticamente por apellido. */
SELECT MAX(apellido), MIN(apellido) FROM Empleados;
/* Ejemplo: consultar la fecha de contratación de empleado más antigua */
SELECT MAX(fecha_contratacion) FROM Empleados;
/* Ejemplo: consultar la fecha de contratación de empleado más nueva */
SELECT MIN(fecha_contratacion) FROM Empleados;
1.4.1 Sentencia GROUP BY:
La sentencia GROUP BY se utiliza para agrupar filas que tienen los mismos valores en una o más columnas. Esta sentencia es esencial cuando necesitamos realizar operaciones de agregación, como sumar, contar o calcular promedios, sobre grupos de filas relacionadas. Por ejemplo, podemos utilizar GROUP BY para calcular el total de ventas por cliente, el número de empleados por departamento o la suma de ventas por producto.
Sintaxis:
-- Sitaxis básica
SELECT columna1, columna2, funcion_agregacion(columna)
FROM tabla
GROUP BY columna1, columna2;
-- Ejemplo: Contar número de empleados de cada departamento:
SELECT departamento, COUNT(*) AS total_empleados
FROM empleados
GROUP BY departamento;
-- Ejemplo 2
SELECT Departamento, AVG(Salario) AS SalarioPromedio
FROM Empleados
GROUP BY Departamento;
Esta consulta nos devolverá el nombre de cada departamento junto con el salario promedio de los empleados que trabajan en ese departamento. Esto puede ser útil para tener una idea de cómo se distribuyen los salarios en diferentes áreas de una empresa.
SELECT Departamento, AVG(Salario) AS SalarioPromedio: Esta parte de la consulta indica que queremos seleccionar dos cosas: el nombre del departamento (Departamento) y el salario promedio (AVG(Salario)) de los empleados en cada departamento.
AVG()es una función de agregación que calcula el promedio de valores, con AVG(Salario) calcula el promedio de los salarios de todos los empleados en cada departamento.AS SalarioPromedioasigna un alias «SalarioPromedio» al resultado del cálculo del promedio de salario. Esto significa que en los resultados de nuestra consulta, en lugar de ver «AVG(Salario)», veremos «SalarioPromedio», lo que hace que el resultado sea más claro y legible.
FROM Empleados: Aquí especificamos la tabla de la cual queremos seleccionar los datos. En este caso, estamos seleccionando los datos de la tabla «Empleados».
GROUP BY Departamento: Esta parte de la consulta agrupa los resultados por el campo «Departamento». Esto significa que los resultados se dividirán en grupos, uno para cada departamento único en la tabla de empleados.
1.4.2 Sentencia HAVING:
La cláusula HAVING se utiliza junto con la sentencia GROUP BY para filtrar grupos de filas basadas en condiciones específicas después de aplicar funciones de agregación. Mientras que la cláusula WHERE se aplica antes de que se agrupen los datos, HAVING se aplica después de que se hayan formado los grupos. Esto nos permite filtrar los resultados basados en el resultado de las funciones de agregación, como el total de ventas, el promedio de salario, etc.
-- Sitaxis básica
SELECT columna, funcion_agregacion
FROM tabla
GROUP BY columna
HAVING condicion;
En el siguiente ejemplo está calculando el salario promedio por departamento y luego filtrando los resultados para incluir solo aquellos departamentos donde el salario promedio es mayor que 50000.
-- Ejemplo
SELECT departamento, AVG(salario) AS salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG(salario) > 50000;
Ejercicio Nº 9 : Declaración de conlsultas.
Sobre el caso práctico de la base de datos del diagrama siguiente realizar las consultas que se piden:
- Número de partidos jugados en febrero.
- Id de equipo y suma de las alturas de sus jugadores.
- Id de equipo y salario total de cada equipo para equipos con más de 4 jugadores registrados.
- Número de ciudades distintas.
- Datos del jugador más alto. (No hemos visto todavía subconsultas en el WHERE, es un avance a la siguiente unidad).
<< Resolución >>
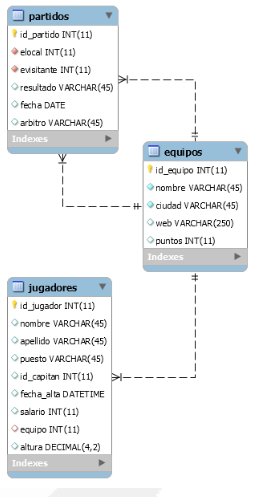
Ejercicio Nº 10 : Declaración de conlsultas 2.
Sobre el caso práctico de la base de datos del diagrama siguiente, realizar las consultas que se piden:
- Datos de los jugadores con equipo, más nombre del equipo y ciudad.
- Datos de los jugadores libres (sin equipo).
- Datos de todos los jugadores, mostrando el nombre de su equipo si lo tienen.
- Es la primera jornada y queremos saber las ciudades de los equipos que aún no han jugado como locales.
- Tras la primera jornada queremos saber un listado de las ciudades en las que hay equipos junto con el resultado de los partidos que han tenido lugar en ellas.
- Listado de jugadores, con el nombre y apellidos de su capitán al lado si lo tienen.
- Es la sexta jornada y queremos sacar todos los equipos y, si se han enfrentado con el Alcoyano como locales, poner el resultado.
<< Resolución >>
1.5 Actualización de datos:
La actualización de datos se realiza utilizando la sentencia UPDATE, que permite modificar los valores de una o más filas en una tabla.
Sintaxis:
UPDATE nombre_de_la_tabla
SET columna1 = valor1, columna2 = valor2, ...
WHERE condiciones;
Ejemplo: En el ejemplo podemos ver como utilizando la sentencia UPDATE podemos modificar los atributos de la tabla Empleados y con la sentencia SET indicamos la columna que queremos modificar (en este caso modificaremos la columna Salario para añadir un nuevo valor «3000»). Finalmente al igual que en los anteriores ejemplos, utilizaremos la sentencia WHERE para especificar que solo modificaremos las columnas cuyo nombre sea «Juan».
UPDATE Empleados
SET Salario = 3000
WHERE Nombre = 'Juan';
1.6 Eliminación de datos:
La eliminación de datos se realiza utilizando la sentencia DELETE FROM, que permite eliminar una o más filas de una tabla.
Sintaxis:
DELETE FROM nombre_de_la_tabla
WHERE condiciones;
Ejemplo: Para este ejemplo utilizaremos la sentencia DELETE FROM para eliminar de la tabla Empleados todo aquellas columnas cuya Edad sea mayor a 40.
DELETE FROM Empleados
WHERE Edad > 40;
Estas son las principales operaciones de manipulación de datos que se pueden realizar utilizando SQL. Es importante tener en cuenta que estas operaciones pueden afectar significativamente los datos en una Base de Datos, por lo que se deben realizar con precaución y atención a los detalles. Además, es importante asegurarse de tener los permisos adecuados para realizar estas operaciones según las políticas de seguridad de la Base de Datos.
2. Gestión de Usuarios
La gestión de usuarios en SQL y en las bases de datos en general consiste en administrar quién puede acceder a la base de datos y qué acciones pueden realizar una vez que están dentro. Esto incluye la creación, modificación y eliminación de usuarios, así como la asignación de roles, privilegios y permisos.
2.1. Creación de Usuarios
Crear usuarios en SQL es importante porque nos permite controlar quién puede acceder a la base de datos y qué pueden hacer dentro de ella. Al crear un usuario, también podemos asignarle diferentes funciones y privilegios para limitar o permitir sus acciones según sea necesario. Esto es fundamental para garantizar la seguridad y la integridad de los datos en la base de datos.
Para crear un usuario en SQL, normalmente se utiliza la sentencia CREATE USER.
Sintaxis:
CREATE USER user
IDENTIFIED BY password;
Por ejemplo, si queremos crear un usuario llamado «usuario1» con una contraseña «contraseña123», la sentencia sería algo así:
CREATE USER usuario1 IDENTIFIED BY contraseña123;
Esta sentencia crea un nuevo usuario llamado «usuario1» y le asigna la contraseña «contraseña123». Ahora, este usuario puede iniciar sesión en la base de datos utilizando el nombre de usuario y la contraseña especificados.
Los usuarios en SQL pueden tener diferentes funciones y privilegios, que se pueden asignar utilizando la sentencia GRANT. Por ejemplo, si queremos darle al usuario «usuario1» el privilegio de seleccionar datos de una tabla llamada «tabla1», la sentencia sería así:
GRANT SELECT ON tabla1 TO usuario1;
Con esta sentencia, le estamos otorgando al usuario «usuario1» el permiso de seleccionar datos de la tabla «tabla1». Esto significa que el usuario puede realizar consultas de lectura en esa tabla, pero no puede modificar los datos.
2.1.1 Error ORA-65096: Nombre de usuario o rol común no válido.
En algunas ocasiones puede que nos aparezca el error ORA.65096 a la hora de intentar crear un nuevo usuario en el sistema de bases de datos de Oracle. Para solucionar este error, basta con ejecutar la siguiente sentencia:
ALTER SESSION SET "_ORACLE_SCRIPT"=true;
_ORACLE_SCRIPT: Es una variable interna de Oracle que controla cómo se interpretan los identificadores (como nombres de usuarios, tablas, etc.) en ciertos contextos dentro de las sentencias SQL. Cuando _ORACLE_SCRIPT está establecido en true, Oracle permite la creación de usuarios con nombres que podrían considerarse comunes.
Al establecer _ORACLE_SCRIPT en true, estás indicando a Oracle que ignore temporalmente esta restricción al crear usuarios. Esto permite la creación de usuarios con nombres que podrían considerarse comunes, como en tu caso.
2.1.2 Conocer nuestro usuario actual.
En una terminal de SQL de Oracle, puedes utilizar la función USER para conocer el usuario actualmente conectado. Simplemente ejecuta la siguiente consulta:
SELECT USER FROM DUAL;
Esto te devolverá el nombre del usuario que está actualmente conectado a la sesión de Oracle.
2.1.3 Cómo conocer todos los usuarios del sistema.
Para ver todos los usuarios en una base de datos Oracle, puedes consultar la vista del diccionario de datos llamada DBA_USERS o ALL_USERS. Esta vista contiene información sobre todos los usuarios en la base de datos. Aquí tienes la consulta para obtener una lista de todos los usuarios:
SELECT username FROM all_users;
Esta consulta devolverá una lista de nombres de usuario de todos los usuarios existentes en la base de datos. Ten en cuenta que es posible que necesites permisos adecuados (como el privilegio SELECT ANY DICTIONARY) para acceder a la vista DBA_USERS, dependiendo de tu configuración de seguridad. Si no tienes acceso a DBA_USERS, puedes intentar con la vista ALL_USERS, que mostrará los usuarios a los que tienes acceso.
2.2 Eliminar Usuario
Eliminar usuarios en SQL es un proceso importante para mantener la seguridad y la integridad de la base de datos. Aquí te explico cómo eliminar usuarios de una manera sencilla:
Para eliminar un usuario en SQL, se utiliza la sentencia DROP USER, seguida del nombre del usuario que se desea eliminar. Por ejemplo, si queremos eliminar un usuario llamado «usuario1», la sentencia sería algo así:
DROP USER usuario1;
Al ejecutar esta sentencia, el usuario «usuario1» y todos sus objetos asociados, como tablas, vistas y privilegios, serán eliminados de la base de datos. Es importante tener en cuenta que esta acción es irreversible y que todos los datos y objetos del usuario serán eliminados permanentemente.
Es importante tener cuidado al eliminar usuarios, ya que esto puede tener un impacto significativo en la seguridad y la integridad de la base de datos. Antes de eliminar un usuario, asegúrate de verificar que no tenga ningún objeto importante asociado y de que ningún otro usuario dependa de él para acceder a la base de datos o realizar tareas específicas.
Eliminar usuarios en SQL es un proceso sencillo que se realiza utilizando la sentencia DROP USER, pero es importante tener cuidado y verificar que la eliminación del usuario no afecte negativamente la seguridad o la integridad de la base de datos.
2.2.1 Error ORA-28014: no se puede borrar el rol o el usuario administrativo
En algunas ocasiones puede que nos aparezca el error ORA.28014 a la hora de intentar crear un nuevo usuario en el sistema de bases de datos de Oracle. Para solucionar este error, basta con ejecutar la siguiente sentencia:
ALTER SESSION SET "_ORACLE_SCRIPT"=true;
3. Permisos básicos de Usuario
Al crear un nuevo usuario en una base de datos Oracle SQL, los permisos que otorgues dependerán de las necesidades específicas del usuario y de las aplicaciones que utilizará. Sin embargo, aquí tienes una lista de permisos comunes que podrías considerar otorgar de forma general:
CREATE SESSION: Este es un permiso básico que permite al usuario iniciar una sesión en la base de datos. Sin este permiso, el usuario no podrá conectarse a la base de datos.
CREATE TABLE: Permite al usuario crear nuevas tablas en su propio esquema de base de datos.
CREATE VIEW: Permite al usuario crear vistas en su propio esquema de base de datos.
CREATE SEQUENCE: Permite al usuario crear secuencias en su propio esquema de base de datos.
CREATE PROCEDURE: Permite al usuario crear procedimientos almacenados en su propio esquema de base de datos.
CREATE TRIGGER: Permite al usuario crear disparadores en su propio esquema de base de datos.
CREATE SYNONYM: Permite al usuario crear sinónimos en su propio esquema de base de datos.
SELECT ANY TABLE: Este permiso otorga al usuario el derecho de seleccionar datos de cualquier tabla en la base de datos. Esto puede ser útil en situaciones donde el usuario necesita acceder a datos de múltiples tablas.
INSERT, UPDATE, DELETE: Estos permisos permiten al usuario realizar operaciones de inserción, actualización y eliminación en tablas específicas.
ALTER SESSION: Este permiso permite al usuario alterar la configuración de su sesión, como el idioma de la sesión o el ajuste de parámetros de sesión específicos.
Es importante evaluar cuidadosamente los permisos que otorgas a un usuario para garantizar la seguridad y la integridad de la base de datos. Además, ten en cuenta que estos son solo ejemplos de permisos comunes y que pueden variar según los requisitos específicos de tu aplicación y las políticas de seguridad de tu organización.
3.1. Asignar todos los permisos (Para crear Usuarios Admin Independientes).
No es recomendable asignar todos los permisos a un usuario por motivos de seguridad, pero para no liarnos al principio, podéis ejecutar la siguiente sentencia desde el usuario principal (con privilegios sysdba).
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW, CREATE SEQUENCE, CREATE PROCEDURE, CREATE TRIGGER, CREATE SYNONYM, SELECT ANY TABLE, INSERT ANY TABLE, UPDATE ANY TABLE, DELETE ANY TABLE, ALTER SESSION TO nombre_de_usuario;
GRANT CREATE SESSION,
CREATE TABLE,
CREATE VIEW,
CREATE SEQUENCE,
CREATE PROCEDURE,
CREATE TRIGGER,
CREATE SYNONYM,
SELECT ANY TABLE,
INSERT ANY TABLE,
UPDATE ANY TABLE,
DELETE ANY TABLE,
ALTER SESSION TO nombre_de_usuario;
Ejercicio Nº 11 : Declaración de consultas 3
Sobre el caso práctico de la base de datos del diagrama del esquema HR de Oracle realizar las consultas que se piden:
- Consultar el nombre del departamento y su mánager.
- Repetir la consulta anterior, para que aparezca primero el mánager y luego el nombre del departamento.
- Consultar el nombre, el apellido, el salario y la fecha de contratación de los empleados.
- Consultar el id del país, su nombre y el id del continente al que pertenece.
- Consultar todos los datos almacenados en la tabla de trabajos.
- Consultar todos los datos almacenados en la tabla que almacena los continentes o regiones.
- Consultar el apellido, el salario y el salario mensual (salario divido entre 12) de un empleado.
- Consultar el apellido, id del trabajo y salario de un empleado concatenando el valor de estas columnas y renombrado la columna resultante de manera identificativa.
4. Funciones de Agregación
Las funciones de agregación son herramientas poderosas en SQL que nos permiten realizar cálculos sobre conjuntos de datos, como sumar, promediar, contar, encontrar el valor mínimo o máximo, entre otros. Aquí tienes una explicación de las funciones de agregación más comunes.
4.1 SUM, AVG, COUNT, MIN, MAX
Funciones de agregado básicas:
- SUM: Calcula la suma de los valores en una columna específica.
- AVG: Calcula el promedio de los valores en una columna específica.
- COUNT: Cuenta el número de filas o valores en una columna específica.
- MIN: Encuentra el valor mínimo en una columna específica.
- MAX: Encuentra el valor máximo en una columna específica.
Estas funciones se aplican generalmente junto con la cláusula GROUP BY para calcular estos valores para grupos de datos en lugar de para la totalidad de la tabla.
Funciones de Agregado con Distinción:
Estas funciones tratan los valores duplicados como un solo valor al realizar el cálculo.
COUNT(DISTINCT columna): contará solo los valores únicos en la columna especificada.
Funciones de Agregado de Valor de Ventana:
Estas funciones calculan un valor en función de un conjunto de filas relacionadas con la fila actual.
- Ejemplos incluyen
SUM() OVER(),AVG() OVER(),ROW_NUMBER(), etc.
4.2 Uso de funciones de agregación en consultas
Estas funciones de agregación se pueden utilizar en consultas para realizar cálculos sobre los datos de una tabla. Aquí tienes un ejemplo de cómo se utilizan:
SELECT
SUM(Salario) AS TotalSalarios,
AVG(Salario) AS SalarioPromedio,
COUNT(*) AS TotalEmpleados,
MIN(Salario) AS SalarioMinimo,
MAX(Salario) AS SalarioMaximo
FROM Empleados;
En este ejemplo, estamos utilizando varias funciones de agregación para calcular diferentes métricas sobre los salarios de los empleados en la tabla «Empleados». Estamos calculando la suma total de salarios, el salario promedio, el número total de empleados, el salario mínimo y el salario máximo.
Las funciones de agregación son extremadamente útiles para resumir y analizar grandes conjuntos de datos en SQL, lo que nos permite obtener información útil y estadísticas sobre nuestros datos de manera rápida y eficiente.
Ejercicio Nº 12 : Declaración de consultas 4
Sobre el caso práctico de la base de datos del diagrama del esquema HR de Oracle realizar las consultas que se piden:
- Desarrolle una consulta que muestre solo los nombres de los empleados que no se repiten.
- Hallar el salario medio, el máximo y el mínimo para cada grupo de empleados por puesto de trabajo, mostrar sólo los que tienen el puesto de trabajo REP y el salario medio excede a 8000
<< Resolución >>
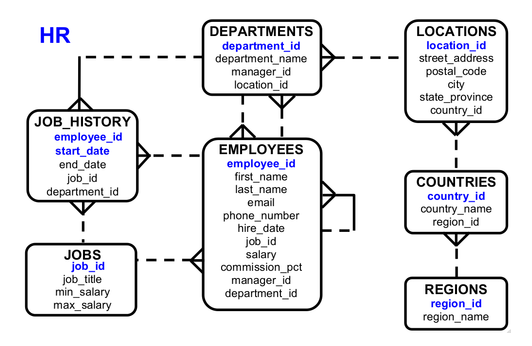
Ejercicio Nº 13 : Declaración de consultas 5
Sobre el caso práctico de la base de datos del diagrama del esquema HR de Oracle realizar las consultas que se piden:
- Consultar los países asociados a cada continente, las columnas que se desea que aparezcan como parte de esta columna son: region_id, region_name, country_name.
- Consultar los departamentos que se encuentran ubicados fuera de estados unidos.
- Consultar todos los países que pertenezcan al continente asiático.
- Para cada departamento obtener la ciudad donde se encuentra situado (city), y el id de su localización (location_id). Realizar esta consulta mediante NATURAL JOIN.
- Para cada departamento obtener la ciudad donde se encuentra situado (city), teniendo en cuenta que la ciudad donde está situado el departamento no puede empezar por S. Realizar esta consulta mediante USING.
- Consultar los nombres de empleados y nombre sus departamentos correspondientes.
<< Resolución >>
5. Subconsultas y Joins
Las subconsultas y los Joins son herramientas fundamentales en SQL que nos permiten realizar consultas complejas y combinar datos de diferentes tablas. Aquí tienes una explicación de cada uno:
5.1 Subconsultas simples y correlacionadas
- Subconsultas simples: Son consultas anidadas dentro de una consulta principal. Se ejecutan primero y luego se utiliza su resultado en la consulta principal.
SELECT columna
FROM tabla
WHERE columna IN (SELECT columna FROM otra_tabla);
- Subconsultas correlacionadas: Son subconsultas que hacen referencia a una columna de la consulta principal, lo que las hace dependientes de la fila actual de la consulta principal.
SELECT nombre
FROM productos
WHERE id = (
SELECT id_producto
FROM ventas
GROUP BY id_producto
ORDER BY COUNT(*) DESC
LIMIT 1
);
Subconsulta:
La subconsulta (SELECT id_producto FROM ventas GROUP BY id_producto ORDER BY COUNT(*) DESC LIMIT 1) encuentra el ID del producto más vendido en la tabla «ventas»:
GROUP BY id_productoagrupa las ventas por ID de producto.ORDER BY COUNT(*) DESCordena los grupos en orden descendente según el número de ventas.LIMIT 1devuelve solo la primera fila, que corresponde al producto más vendido.
Consulta principal:
La consulta principal selecciona el nombre del producto de la tabla «productos» donde el ID coincide con el ID del producto más vendido encontrado en la subconsulta.
Esta consulta nos devolverá el nombre del producto más vendido. Es un ejemplo claro de cómo usar una subconsulta para obtener información específica basada en los datos de otra tabla.
5.2 Tipos de Joins: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN
- INNER JOIN: Devuelve solo las filas que tienen coincidencias en ambas tablas.
SELECT *
FROM tabla1
INNER JOIN tabla2
ON tabla1.columna = tabla2.columna;
- LEFT JOIN: Devuelve todas las filas de la tabla izquierda y las filas coincidentes de la tabla derecha.
SELECT *
FROM tabla1
LEFT JOIN tabla2
ON tabla1.columna = tabla2.columna;
RIGHT JOIN: Devuelve todas las filas de la tabla derecha y las filas coincidentes de la tabla izquierda.
SELECT *
FROM tabla1
RIGHT JOIN tabla2
ON tabla1.columna = tabla2.columna;
FULL JOIN: Devuelve todas las filas cuando hay una coincidencia en una de las tablas. Si no hay coincidencias, NULL se incluirá en las columnas sin coincidencia.
SELECT *
FROM tabla1
FULL JOIN tabla2
ON tabla1.columna = tabla2.columna;
5.3 Combinar datos de múltiples tablas con INNER JOIN
Los Joins se utilizan para combinar datos de múltiples tablas basándose en una condición de relación entre ellas. Son útiles cuando necesitamos obtener información que está distribuida en diferentes tablas y queremos combinarla en una sola consulta.
SELECT *
FROM clientes
INNER JOIN pedidos
ON clientes.id = pedidos.id_cliente;
En este ejemplo, estamos utilizando un INNER JOIN para combinar la información de la tabla «clientes» con la tabla «pedidos» basándonos en el campo «id_cliente». Esto nos permitirá obtener información sobre los clientes y los pedidos que han realizado.
5.4 Combinar datos de múltiples tablas con NATURAL JOIN
NATURAL JOIN es una cláusula de SQL que se utiliza para combinar dos tablas en función de las columnas que tienen el mismo nombre en ambas tablas. En otras palabras, realiza una unión entre dos tablas utilizando las columnas que comparten el mismo nombre y, por lo tanto, se consideran naturalmente relacionadas.
Por ejemplo, supongamos que tienes dos tablas: clientes y pedidos, y ambas tienen una columna llamada id_cliente. Al utilizar NATURAL JOIN, la unión se realizaría automáticamente en función de la columna id_cliente que ambas tablas tienen en común. La sintaxis sería algo como:
SELECT *
FROM clientes
NATURAL JOIN pedidos;
En este caso, la unión se realizaría en base a la columna id_cliente.
La principal diferencia entre NATURAL JOIN y otros tipos de JOIN (como INNER JOIN o LEFT JOIN) radica en cómo se determina la condición de unión entre las tablas:
NATURAL JOINno requiere especificar explícitamente las columnas en las que se basa la unión, ya que utiliza automáticamente todas las columnas con nombres coincidentes.- Por otro lado, con
INNER JOIN,LEFT JOIN, u otros tipos deJOIN, debes especificar las columnas en las que deseas basar la unión utilizando la cláusulaON.
Por lo tanto, NATURAL JOIN puede ser más conveniente y conciso en ciertos casos donde las tablas tienen columnas con nombres comunes y se desea realizar una unión basada en esas columnas. Sin embargo, debido a la falta de control explícito sobre las columnas de unión, algunos desarrolladores prefieren evitar su uso en favor de los JOIN explícitos para mayor claridad y control sobre la consulta.
Ejercicio Nº 14 : Consultas usando OUTER JOIN
Sobre el caso práctico de la base de datos del diagrama siguiente, realizar las consultas que se piden:
- Datos de los jugadores con equipo, más nombre del equipo y ciudad.
- Datos de los jugadores libres (sin equipo).
- Datos de todos los jugadores, mostrando el nombre de su equipo si lo tienen.
- Es la primera jornada y queremos saber las ciudades de los equipos que aún no han jugado como locales.
- Tras la primera jornada queremos saber un listado de las ciudades en las que hay equipos junto con el resultado de los partidos que han tenido lugar en ellas.
- Listado de jugadores, con el nombre y apellidos de su capitán al lado si lo tienen.
- Es la sexta jornada y queremos sacar todos los equipos y, si se han enfrentado con el Alcoyano como locales, poner el resultado.
<< Resolución >>
5.5 Combinar datos de múltiples tablas con USING
La cláusula USING en SQL se utiliza en las operaciones de JOIN para especificar explícitamente las columnas que se utilizarán para la unión entre dos tablas. A diferencia de NATURAL JOIN, que une las tablas utilizando todas las columnas con el mismo nombre, USING te permite especificar las columnas específicas que deseas utilizar para la unión.
El funcionamiento de USING es bastante simple: solo especificas el nombre de las columnas que se utilizarán para la unión después de la palabra clave USING. Estas columnas deben tener el mismo nombre y tipo de datos en ambas tablas.
Aquí tienes un ejemplo de cómo se utiliza USING en una consulta SQL:
Supongamos que tienes dos tablas, empleados y departamentos, y deseas unir estas tablas en función de la columna departamento_id. Puedes hacerlo de la siguiente manera utilizando USING:
SELECT *
FROM pedidos
JOIN clientes USING (id_pedido, id_cliente);
USING (departamento_id) especifica que la unión debe realizarse utilizando la columna departamento_id en ambas tablas.Otro ejemplo podría ser si deseas unir dos tablas en función de múltiples columnas. Por ejemplo, si tienes las tablas pedidos y clientes, y deseas unir las filas donde tanto el id_pedido como el id_cliente coincidan, puedes hacerlo así:
SELECT *
FROM pedidos
JOIN clientes USING (id_pedido, id_cliente);
En este caso, la unión se realizará utilizando las columnas id_pedido e id_cliente.
La cláusula USING es especialmente útil cuando las columnas utilizadas para la unión tienen el mismo nombre en ambas tablas y deseas evitar la redundancia al especificar las condiciones de unión. Sin embargo, ten en cuenta que USING no se puede utilizar si las columnas tienen diferentes nombres en las tablas que estás uniendo. En ese caso, deberías usar ON para especificar las condiciones de unión.
Ejercicio Nº 15 : Declaración de subconsultas 1
Sobre el caso práctico de la base de datos del diagrama siguiente, realizar las consultas que se piden:
- Datos del jugador más alto.
- Suma de alturas de los jugadores del Cai y del Madrid.
- Datos de jugadores de equipos que hayan jugado algún partido contra el valencia en casa.
- Nombre de jugadores que midan más que todos los del caja laboral.
- Datos de jugadores cuyo salario sea mayor que el de sus capitanes.
- Datos del equipo con más jugadores registrados.
- Nombre de los jugadores mejor y peor pagados.
<< Resolución >>
6. Funciones de conversión.
En Oracle SQL, las funciones de conversión se utilizan para convertir valores de un tipo de datos a otro. Estas funciones son útiles cuando necesitas cambiar el tipo de datos de una columna en una consulta o realizar operaciones con diferentes tipos de datos. Aquí tienes algunos tipos de funciones de conversión comunes en Oracle SQL, junto con ejemplos de cada uno:
6.1 TO_CHAR:
6.1.1 Convertir valores de tipo fecha con TO_CHAR:
Esta función se utiliza para convertir valores de tipos de datos numéricos o de fecha a cadenas de caracteres.
SELECT TO_CHAR(SYSDATE, 'DD-MM-YYYY') AS fecha_actual FROM dual;
Este ejemplo convierte la fecha actual del sistema (SYSDATE) en una cadena de caracteres con el formato ‘DD-MM-YYYY’.
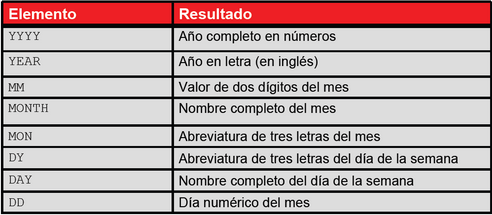
Por ejemplo el modelo de formato (‘format_model’) de fecha y hora ’11-NOV-1999’ es ‘DD-MON-YYYY’ (dos números para el día del mes, un guion, las tres primeras letras del nombre del mes, un segundo guion y los cuatro números del año).
Respecto al modelo de formato, se debe tener en cuenta:
- Debe estar entre comillas simples.
- Es sensible a mayúsculas y minúsculas.
- Puede incluir cualquier elemento de formato de fecha válida.
- Debe estar separado del dato mediante una coma.
En la imagen siguiente, se muestran los distintos elementos del formato fecha.
6.1.2 Convertir valores de tipo numérico con TO_CHAR:
La función TO_CHAR también se puede utilizar para mostrar un valor numérico como una cadena de caracteres.

Podemos ver un ejemplo de consulta que utiliza la función TO_CHAR con valores numéricos (el signo del dólar delante, la parte entera y la decimal separadas por un punto).
SELECT TO_CHAR(Salary, '$99,999.000') AS salary FROM Employees WHERE last_name='Manolo';
Una vez ejecutado, Oracle nos proporcionará la siguiente respuesta:
SALARY
---------
$6,000.00
6.2 TO_NUMBER:
Esta función se utiliza para convertir valores de tipos de datos numéricos o de fecha a cadenas de caracteres.
Este ejemplo convierte la cadena de caracteres ‘123.45’ en un número decimal.
SELECT TO_NUMBER('123.45') AS numero_convertido FROM dual;
6.3 TO_DATE:
Utilizada para convertir cadenas de caracteres en valores de fecha.
Este ejemplo convierte la cadena de caracteres ‘2022-04-26’ en un valor de fecha.
SELECT TO_DATE('2022-04-26', 'YYYY-MM-DD') AS fecha_convertida FROM dual;
6.4 CAST:
Esta función se utiliza para convertir valores de un tipo de datos a otro.
Este ejemplo convierte la cadena de caracteres ‘123’ en un número.
SELECT CAST('123' AS NUMBER) AS numero_convertido FROM dual;
6.5 CONVERT:
Utilizada para convertir una expresión de un tipo de datos a otro.
Este ejemplo convierte la cadena de caracteres ‘HELLO’ a un valor de caracteres nacionales.
SELECT CONVERT('HELLO' USING NCHAR_CS) AS texto_convertido FROM dual;
Estos son solo algunos ejemplos de las funciones de conversión disponibles en Oracle SQL. La elección de la función dependerá del tipo de conversión que necesites realizar y de la versión específica de Oracle SQL que estés utilizando.